
Content Marketing
Powerful PPC Optimization Tactics to Maximize Your Spend
Unlock powerful PPC optimization strategies that elevate your campaigns beyond basics. Learn expert...


In this article we dive into how to take control of crawl access and block ChatGPT users using robots.txt while exploring the bumps and hiccups you might encounter along the way.
Blocking ChatGPT user from robots.txt is vital when it comes to protecting your valuable resources and data. This control measure isn’t just a neat trick—it can significantly cut down on unwanted scraping and keep a tighter leash on how AI tools handle your content.
The robots.txt file is a plain text file sitting right at the root of a website, quietly telling web crawlers which parts they’re welcome to roam and which areas are off-limits. Think of it as a straightforward little note passed between your server and those persistent crawlers, gently steering their actions.
You find yourself needing to block certain bots or crawlers whether it’s to protect your website’s precious bandwidth or stop content theft or automated scraping that could gum up the user experience.
More website owners are raising an eyebrow about privacy and copyright and who owns their content in the age of AI tools like ChatGPT. Since ChatGPT pulls from a vast sea of scraped web data to generate or process content, putting up a blockade can be a clever way to prevent your hard-earned material from being recycled without a nod or a wink.
ChatGPT doesn’t go around crawling websites like your typical search engines do. Instead, the data usually comes from third-party scrapers or API users who feed information to the AI models.
Robots.txt is more of a gentlemen's agreement in the web world—it's a voluntary standard that relies on crawlers actually playing nice and following its rules, rather than having those rules forced on them by the server.
ChatGPT doesn’t actually crawl websites on its own but relies on data that often comes from scrapers or crawlers doing the legwork. Because of this, nailing down specific user-agents or IP addresses tied directly to ChatGPT is a bit like chasing shadows.
[blockquote attributes={"content":"\u201cRobots.txt can only guide well-behaved crawlers; it is not a security tool and cannot stop unauthorized scraping or data harvesting that ignores these guidelines.\u201d"} end]
Block certain crawlers with robots.txt by pinpointing the user-agent strings of the bots you want to keep at bay. Then, slip in disallow rules under those user-agents to prevent them from poking around your entire site or just the parts you would rather keep off-limits.
Locate or create the robots.txt file right in the root directory of your website.
Dig up the user-agent strings for the crawlers you want to kindly keep out.
Pop in the Disallow directive under each user-agent to close off certain sections or the entire site, depending on your game plan.
Double-check your robots.txt file using online tools to make sure the syntax isn’t throwing a tantrum and all your rules are in tip-top shape.
Keep a close eye on your web server logs and analytics afterwards it’s the digital equivalent of watching your plants grow and making sure those crawlers behave as expected.
Double-check your syntax—malformed rules have a sneaky way of accidentally blocking traffic when you least expect it. Treat wildcard patterns with a bit of caution, and don’t forget to include fallback rules.
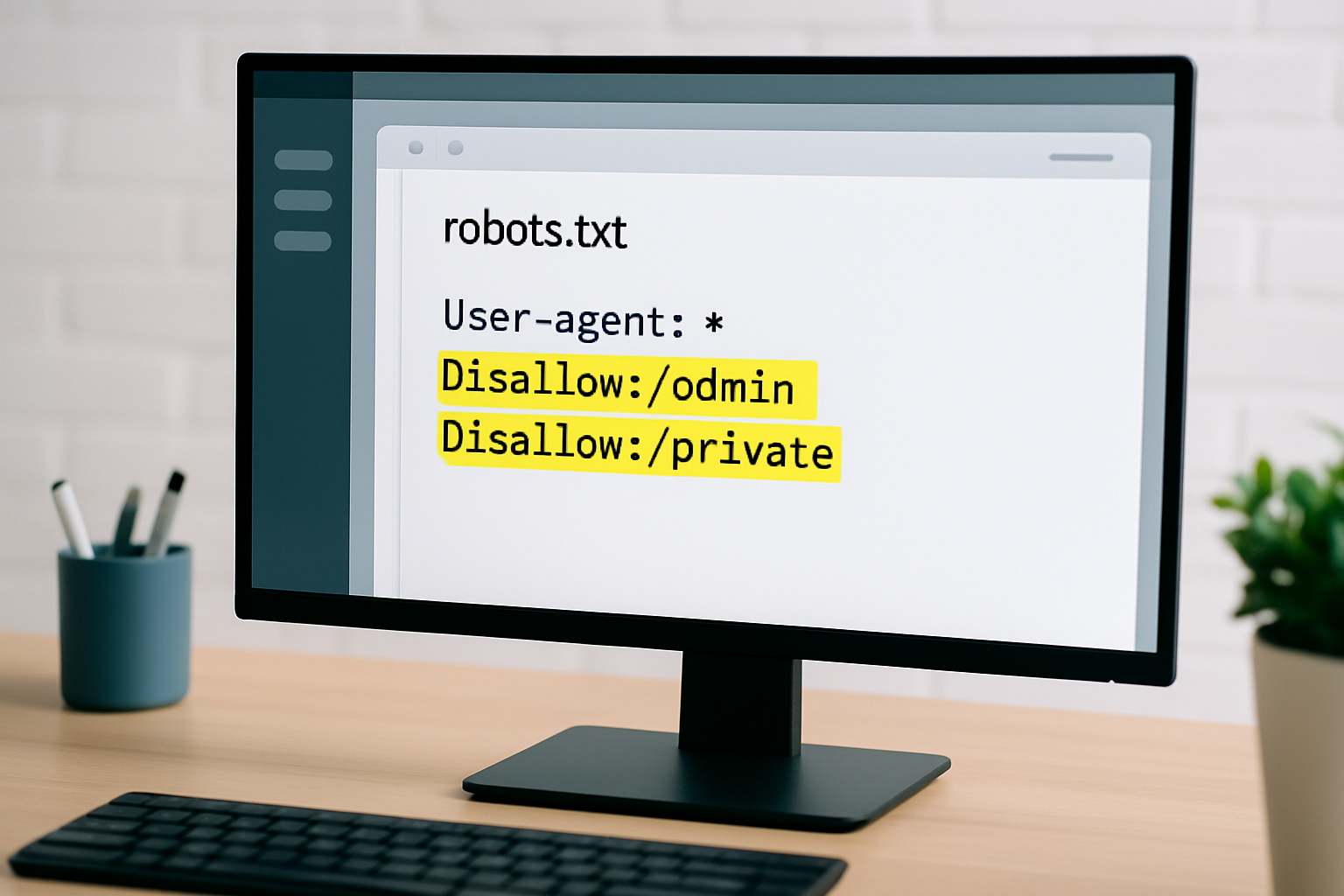
Example of a robots.txt file with user-agent blocking rules to control crawler access
OpenAI's ChatGPT does not use a dedicated crawler, website owners typically keep an eye on ChatGPT-related activity by tracking IP ranges or user-agent patterns linked to third-party services that tap into OpenAI APIs.
Keeping your robots.txt file up to date to block pesky User-agents is an ongoing hustle. It definitely pays off to regularly check your server logs to catch fresh patterns and fine-tune which user-agents you’re blocking while eyeballing how these tweaks influence real crawl traffic.
Give free online tools like Google Search Console's robots.txt tester a spin to check out your file’s syntax and see how well it’s holding up. These handy tools basically put on the crawler’s shoes, following your rules to spot any slip-ups before you flip the switch live.
Upload or update your robots.txt file right in your website's root directory—think of it as your site's front gate keeper.
Then, give that file a once-over using Google Search Console or any good online robots.txt tester you like.
Next, experiment a bit by testing how different user-agents respond to your blocking rules. It is like seeing who follows the signs and who does not.
Check your web server logs to catch crawler activity in action and spot any unusual or quirky patterns.
Finally, keep tweaking and refining those rules over time based on what you observe. Nothing’s ever perfect on the first try.
Beyond just leaning on robots.txt, putting crawl controls on the server side gives you a much sturdier line of defense. Tricks like filtering by IP address and eyeballing user-agents usually do a solid job of cutting down on aggressive scraping and keeping unauthorized data collectors at bay.
These strategies really kick in when robots.txt alone just can’t keep the pesky data scrapers at bay, especially when you’re dealing with valuable content or sensitive user info.
Keeping your robots.txt in tip-top shape means giving it a good once-over now and then, especially when blocking ChatGPT user from robots.txt or noticing other crawler behavior shifts. It’s also a smart move to keep an eye on your server logs to catch any sneaky changes in how bots are poking around your site.
11 pages contributed
With a deep understanding of international markets and cross-cultural nuances, Amir Bakhtiari is an expert in global SEO strategies tailored to diverse audiences worldwide.
Read ArticlesUnlock powerful PPC optimization strategies that elevate your campaigns beyond basics. Learn expert...

Discover how to start your career as a successful SEO analyst with clear explanations, essential ski...

Discover step-by-step restaurant SEO techniques that will enhance your local visibility, attract nea...

Discover how local SEO can transform your restaurant's online presence, bringing in more nearby dine...



